Ihre Daten bleiben bei Ihnen
Alles läuft auf Ihren eigenen Servern oder in einer deutschen Cloud. Ihre Daten verlassen nie Ihr Haus und landen nicht bei großen US-Anbietern.
Kein bloßer KI-Assistent: Unser Produkt ist die Agentic-Hybrid-RAG-Pipeline. Sie macht klassische LLMs stärker und Ihr internes Wissen nutzbar — Assistenten und Apps entstehen nur obendrauf.
>70 % nutzen KI — nur 5,5 % mit messbarem EBIT-Effekt.
R.AgenticRAG schließt die Lücke — KI, die Ihr Firmenwissen belegbar nutzt. McKinsey · The State of AI ↗
DSGVO-konform · On-Premise-fähig · Deutsche Server · Engineered in Germany
Sicher, geprüft, mitdenkend — und gemacht für Ihre technischen Daten.
Alles läuft auf Ihren eigenen Servern oder in einer deutschen Cloud. Ihre Daten verlassen nie Ihr Haus und landen nicht bei großen US-Anbietern.
Wir sind nach ISO 27001 (Informationssicherheit) und ISO 9001 (Qualitätsmanagement) zertifiziert — geprüfte Standards, auf die Sie sich verlassen können.
Statt nur nach Stichwörtern zu suchen, kombiniert unsere KI mehrere Suchwege und denkt in mehreren Schritten mit. So findet sie auch Antworten, die tief in Ihren Unterlagen stecken.
Jede Antwort zeigt, woher sie kommt — mit Verweis auf die genaue Stelle in Ihren Unterlagen. So verlassen Sie sich auf Belege statt blind auf die KI zu vertrauen.
Unsere KI liest Ihre technischen Dateien direkt — von Steuergeräte-Beschreibungen über Messdaten bis zu Stücklisten und Spezifikationen. Gemacht für Fahrzeugentwicklung und Aftersales.
Mit unserem Agentic-Hybrid-RAG-Core erweitern wir bestehende Anwendungen oder bauen neue — fertig aus unserem Portfolio oder ganz nach Ihren Wünschen entwickelt.
Wählen Sie eine Frage und stellen Sie sie einmal ohne und einmal mit R.AgenticRAG. Sehen Sie, welche Datenquellen injiziert werden und wie der Kontext intelligent aufgebaut wird.
Wählen Sie unten eine Frage und klicken Sie auf „Fragen“.
RAG gibt der KI Zugriff auf Ihre eigenen Unterlagen. Sie antwortet nicht aus dem Gedächtnis — sie schlägt die passende Stelle nach.
in normaler Sprache
die KI sucht die Antwort darin
mit Quelle — nachprüfbar
Ohne den mittleren Schritt rät die KI aus dem Gedächtnis. Mit ihm antwortet sie belegt — aus Ihrem Wissen.
Das RAG-Prinzip + Hybrid-Suche + eigenständiger Agent.
Sucht auf drei Wegen gleichzeitig — und nimmt das Beste.
Plant, prüft und verfeinert selbst — wie ein Kollege.
Vom Dokument bis zur fertigen Antwort — jeder Schritt nachvollziehbar, auf Wunsch komplett im eigenen Haus.
Zwei produktionsnahe Use Cases — und einen, den wir mit Ihnen entwickeln.
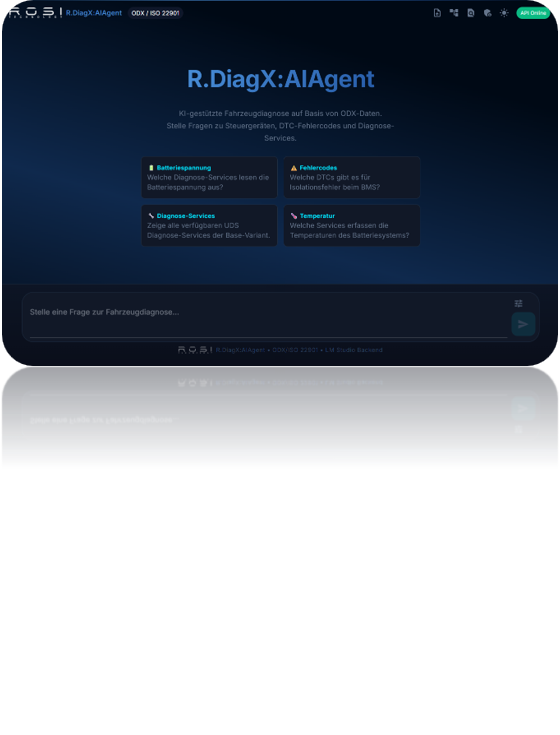
Beantwortet Fragen in natürlicher Sprache — in der Entwicklung zu ODX-Diagnosedaten, DTC-Bedeutungen und Steuergeräten, in der Werkstatt zu Fehlercodes und Reparaturanleitungen. Alles aus internen Daten, ohne dass etwas das Haus verlässt.
Mehr erfahren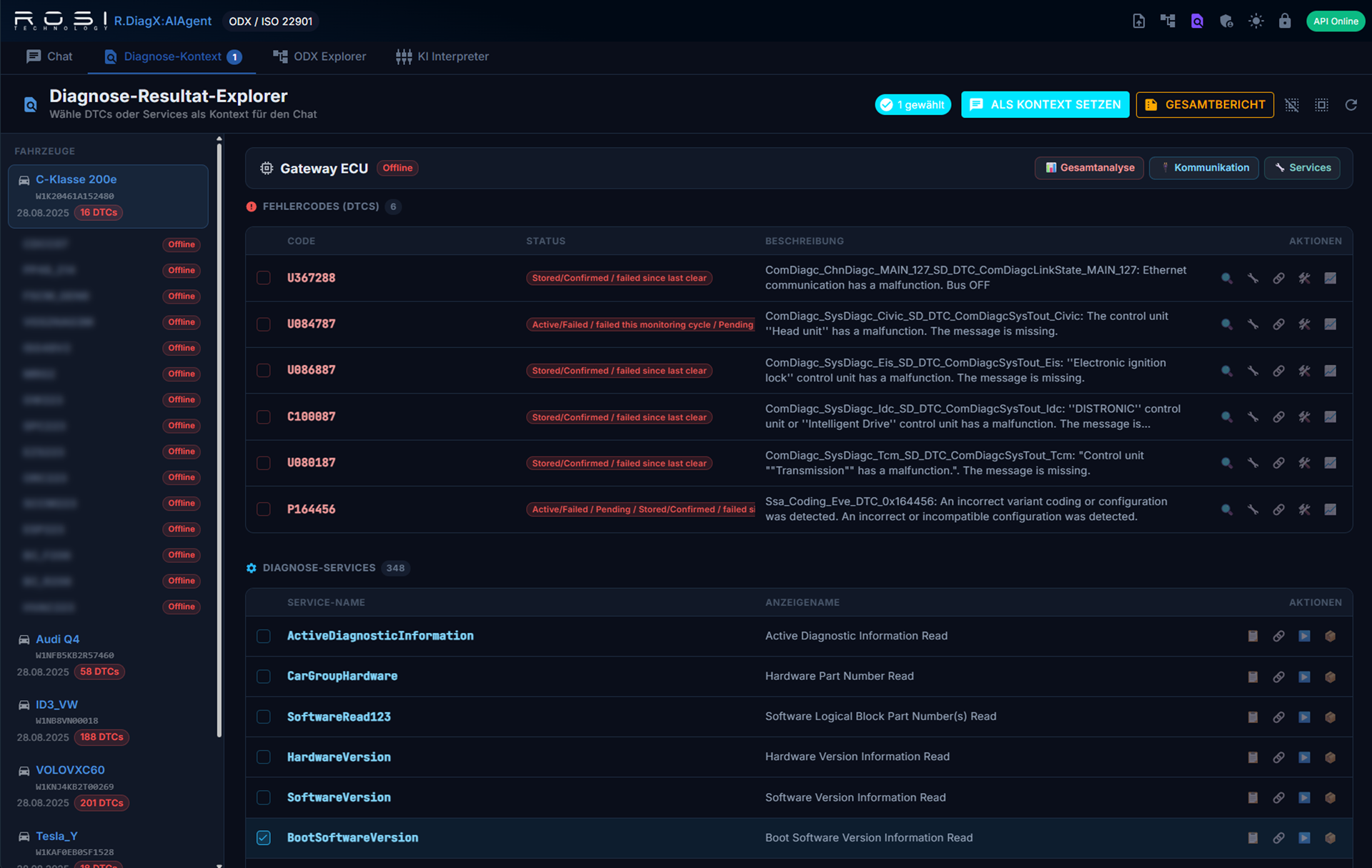
Untersucht Diagnose-Resultate interaktiv: per Klick vordefinierte Informationen und Fragen zu den Ergebnissen abrufen — oder Modelle, Varianten und Dienste schnell miteinander vergleichen.
Mehr erfahrenWir entwickeln gemeinsam die passende On-Top-Applikation für Ihren Use Case. Vom Discovery-Workshop bis zum produktiven Rollout.
Use Case besprechenR.AgenticRAG erkennt neue Tickets selbstständig, recherchiert in allen Wissensquellen und liefert belegte Ergebnisse — rund um die Uhr.
Während der Erprobung des SW-Release 45V fällt im Feld eine Auffälligkeit auf: Ein sporadischer Fehler wird beobachtet und beanstandet.
R.AgenticRAG arbeitet wie ein Mitarbeiter — nur rund um die Uhr und mit Zugriff auf das gesamte Firmenwissen: Es erkennt neue Tickets selbstständig, bearbeitet sie ohne Zutun des Ingenieurs und stellt die Ergebnisse automatisch zu.
Vom Code-Modul über die API bis zu fertigen Anwendungen — Sie entscheiden, wie tief wir einsteigen.
Die Pipeline als eigenständige Komponente.
Die komplette Pipeline als Modul, das in Ihrer Infrastruktur läuft. Ihr Team betreibt und erweitert sie selbst.
Für wen Teams mit eigener Engineering-Abteilung, die maximale Kontrolle wollen.
Brücke in bestehende Workflows und Anwendungen.
Bettet R.AgenticRAG in Ihre vorhandenen Tools ein — Antworten erscheinen dort, wo Ihr Team ohnehin arbeitet.
Für wen Unternehmen, die bestehende Anwendungen um intelligente Suche erweitern wollen.
Fertige Apps oder R.AgenticRAG als Baustein in Automation.
Produktionsbereite Anwendungen für Engineering und Aftersales — oder R.AgenticRAG als Baustein in Ihren autonomen Pipelines.
Für wen Fachbereiche, die schnell starten — oder Teams, die R.AgenticRAG in Automatisierung einbetten. Anwendungen ansehen →
LLM-Inferenz, Datenhaltung und Applikation lassen sich beliebig auf On-Premise, eigene KI-Server oder die deutsche Cloud verteilen. So behalten Sie höchste Flexibilität, volle Individualität und die komplette Hoheit über Ihre Datenflüsse.
Alles im eigenen Haus
Applikation, Daten und Inferenz laufen vollständig auf Ihrer Infrastruktur — kein Byte verlässt Ihr Netz.
Daten lokal, Rechenpower dediziert
Ihre Daten bleiben im Haus, während die LLM-Inferenz auf einem dedizierten KI-/GPU-Server mit voller Performance läuft.
Schlüsselfertig betrieben
Wir betreiben alle Komponenten DSGVO-konform in der deutschen Cloud — Sie nutzen, wir kümmern uns um den Betrieb.
Jede Phase liefert ein Ergebnis. Sie entscheiden, ob wir weitermachen.
Wir verstehen Ihre Ziele — und sagen ehrlich, ob RAG passt.
Eine erste lauffähige Demo mit Ihren Daten — kein Slideware, echtes System.
Echte Datenmengen, Integration und messbare Erfolgskriterien.
Anbindung an Ihre Systeme, Rechte, Monitoring und Schulung.
Wartung, Updates und neue Datenquellen — wir bleiben an Ihrer Seite.
Erfahrung aus Engineering, Forschung und Vertrieb — vereint in einem Team, das KI greifbar macht.

Geschäftsführer (CEO)
Michael verbindet zwei Jahrzehnte Erfahrung in der Fahrzeugentwicklung mit einem klaren Blick für das Machbare. Als Geschäftsführer steckt er die Richtung ab, hört Ihren Anforderungen zu und sorgt dafür, dass aus Forschung echte Produkte werden — pragmatisch, ehrlich und mit dem Anspruch, dass jede Lösung im Alltag bestehen muss.

Technischer Leiter (CTO)
Kordian ist der Architekt unserer Agentic-Hybrid-RAG-Pipeline. Mit tiefer Expertise in KI, Software-Architektur und Datenintegration baut er die Technik, die Ihre Engineering-Daten verstehbar macht — sicher, nachvollziehbar und auf Ihre Infrastruktur zugeschnitten.

Vertrieb & Kundenbeziehungen (Sales)
Moch ist Ihr erster Ansprechpartner — und Übersetzer zwischen Ihrer Welt und unserer Technik. Statt vorgefertigter Pitches stellt er die richtigen Fragen, versteht Ihre Datenlandschaft und sorgt dafür, dass aus dem ersten Gespräch ein Vorhaben wird, das wirklich zu Ihnen passt.
Worüber wir am häufigsten reden — bevor Sie uns anschreiben.
Cloud-LLMs verarbeiten Ihre Anfragen auf Servern, die letztlich US-Gesetzgebung unterliegen — selbst wenn der Anbieter EU-Rechenzentren betreibt, gilt der CLOUD Act für die Mutterfirma. Für Engineering-Daten (Steuergeräte-Code, Konstruktionspläne, Kunden-Spezifikationen) ist das kein Restrisiko, sondern ein Ausschlusskriterium.
Lokale LLMs laufen auf Ihrer Hardware oder in einem Rechenzentrum, das vollständig Ihrer Hoheit untersteht. Kein Token verlässt den Perimeter, kein Telemetrie-Leak, keine Hyperscaler-Abhängigkeit. Zusätzlich: keine Latenz durch Remote-Calls, kein API-Rate-Limit, planbare Kosten.
RAG (Retrieval-Augmented Generation) gibt einem Sprachmodell vor jeder Antwort Zugriff auf Ihre eigenen Dokumente. Ein Retriever holt die relevantesten Ausschnitte, das Modell antwortet ausschließlich auf deren Basis — mit Zitaten und damit prüfbar.
Der Vorteil gegenüber Fine-Tuning: neue Dokumente sind sofort verfügbar (kein Retraining), Halluzinationen sinken drastisch, und Sie behalten die Kontrolle darüber, was das Modell überhaupt sehen darf. Wer welche Antwort bekommt, lässt sich auf Quellenebene steuern — wichtig für vertrauliche Bereiche und Berechtigungsstufen.
Klassisches RAG nutzt einen einzigen Retriever — meist nur Vektor-Suche. Das funktioniert für einfache Faktenfragen, scheitert aber bei komplexen Engineering-Anfragen wie „Welche Steuergeräte beeinflussen die Bremstemperatur in Revision 4.2 und welche DTCs sind neu?“
Drei Punkte, die wir liefern und Sie sonst kaum bekommen:
Dazu unser Vorgehen: Erstgespräch → Demo → Pilot → Rollout. Sie entscheiden nach jeder Phase neu, ob wir weitermachen.
Wir sind ein deutsches Software-Unternehmen aus Leonberg und entwickeln KI für Engineering und Aftersales, die Ihre Daten nicht aus dem Haus lässt. Kern ist R.AgenticRAG — eine Hybrid-Agentic-RAG-Pipeline, die technische Unterlagen (Steuergeräte-Beschreibungen, Messdaten, Pläne, Spezifikationen) direkt liest und belegbare Antworten mit Quellenangabe liefert.
Wir liefern auf drei Ebenen: als Code-Modul (R.AgenticRAG Core) für Ihr eigenes Team, als Integration (R.AgenticRAG:API) in bestehende Anwendungen, oder als fertige Apps für Engineering und Aftersales. Alles läuft on-premise oder in einer deutschen Cloud — zertifiziert nach ISO 27001 und ISO 9001.
Das hängt vom Umfang ab — von einer schlanken API-Anbindung an ein bestehendes Tool bis zur maßgeschneiderten Anwendung. Als grobe Orientierung:
Erstgespräch und eine grobe Datensichtung sind kostenlos — dabei klären wir Datenquellen, Schnittstellen und Zielbild, und Sie bekommen ein belastbares Angebot. Optional setzen wir für wenig Geld einen Proof of Concept auf, mit dem Sie den Nutzen an Ihren eigenen Daten sehen, bevor Sie sich festlegen.
Cloud-LLMs (z. B. GPT, Claude, Gemini) sind geschlossene Modelle, die Sie nur als Dienst über eine API nutzen. Das Modell läuft auf den Servern des Anbieters — Ihre Anfragen verlassen also Ihr Haus, es gelten fremde Nutzungsbedingungen, API-Kosten und Rate-Limits, und der Anbieter kann das Modell jederzeit ändern oder abschalten.
Open-Weight-LLMs (z. B. Llama, Qwen3, Mistral, DeepSeek, Gemma) stellen ihre Modell-Gewichte öffentlich bereit. Sie betreiben das Modell auf Ihrer eigenen Hardware:
Hinweis: Open-Weight heißt „Gewichte frei verfügbar“ — nicht zwingend vollständig Open Source (Trainingsdaten und -code sind nicht immer offen). Genau auf solche lokal betriebenen Open-Weight-Modelle setzt R.AgenticRAG.
Ja. Neben unserem Produkt begleiten wir Unternehmen auch beratend auf dem Weg zu KI — von der ersten Standortbestimmung über die Auswahl sinnvoller Anwendungsfälle bis zur konkreten Umsetzung. Sie bekommen also nicht nur Software, sondern einen Partner, der Technik und Nutzen zusammenbringt.
Wir arbeiten dabei individuell statt von der Stange — zugeschnitten auf Ihre Branche, Datenlage und Ziele. Schildern Sie uns einfach Ihre Anfrage; das Erstgespräch ist kostenlos.
Wir hören erst zu, dann zeigen wir, was geht. Kein Pitch-Marathon — ein konkretes Gespräch über Ihre Datenquellen, Sicherheitsanforderungen und Use Cases.
Schreiben Sie uns direkt — wir antworten innerhalb eines Werktages.
sales@rosi-technology.de
„Erzählen Sie mir von Ihren Datenquellen und Use Cases — gemeinsam finden wir den schnellsten Weg zur passenden Lösung. Unkompliziert, ehrlich und ohne Pitch-Marathon.“
Mit Maxi schreibenEinen Moment — wir verbinden Sie wieder mit dem Server.
Versuch 1 von 8 · nächster in 0 s
Wir konnten den Server nicht erreichen. Bitte prüfen Sie Ihre Internetverbindung.
Die Verbindung wurde zu lange unterbrochen. Bitte laden Sie die Seite neu, um fortzufahren.